CS+ 2022 Symposium and Poster Session
The CS+ summer program held an in-person symposium to conclude the undergraduate research program on July 29, 2022. CS+, Data+, Code+ and Climate+ Programs also held a poster fair on July 29 to celebrate the results of over 100 talented Duke undergraduate students who participated in undergraduate research projects this summer. Nearly 50 posters were displayed at this culminating event, and more than 2/3 of the participating students study CS.
Presentation posters and project descriptions for CS+ 2022 Summer Projects are available below.

Leads: Danyang Zhuo, Matthew Lentz
Participating Students:

Alex Du
I'm a rising junior from Hong Kong majoring in computer science and economics and minoring in Math. I'm interested in research and I hope to pursue a Ph.D. in computer science or economics after graduating.

Ajay Krishnamurthy
I am a rising sophomore from Chapel Hill, North Carolina, studying computer science. I'm interested in pushing the boundaries of machine learning and its intersection with bioinformatics. I also enjoy sports analytics and love to watch and play sports in my free time.

Aining Liu
I'm Aining Liu, an international student from Beijing, China. I'm a rising junior majoring in Computer Science and Mathematics. I'm interested in operating system/distributed system and the design of datacenters that enable modern cloud computing and data-intensive workloads. After graduation, I intend to pursue a Ph.D. in related fields. In my free time, I enjoy playing the piano (Huge Chopin & Liszt fan!), riding roller coasters, and all kinds of puzzle games.
Description: There is growing interest in deploying machine learning models on the edge of the Internet, including distributed video analytics and IoT. Our project’s goal is to enable efficient ML workflow serving on the edge. Given a workflow of ML models, our optimization framework decides which components should be deployed at the sensor, on the edge, or in the cloud. The decisions have to take into consideration the computation power of edge devices (e.g., cellphone, camera, edge servers) and the required amount of edge-cloud communication. In addition, the optimization framework may transform the workflow to enable better decomposition and deployment of components on the computing infrastructure. This project is a hybrid of both theory and practice; it involves both algorithm design along with implementation of the algorithms to evaluate their performance on real-world workloads. Our existing framework consists of a simple, yet powerful, optimizer. We need to invent optimization algorithms to further enhance ML model placement. We also need to build an end-to-end system to support running of complex ML workflows.
Goals/Deliverables: We expect there to be several types of deliverables at the end of the summer:
- Algorithms/Designs: Algorithmic enhancements to our optimization framework at both the logical layer (ML workflow structure and transformations) and physical layer (placement of ML workflow compute tasks on infrastructure)
- Real-world Implementation: Translating theory to practice through implementation of the algorithms/designs on top of our existing distributed ML serving system
Background/Prerequisites:
- Fluent in Python programming;
- Knowledge of low-level programming languages (C, C++, Rust) is a plus;
- General knowledge about machine learning; and
- Prior experience running simple ML models using PyTorch or Tensorflow is preferred but not required.

Lead: Brandon Fain
Participating Students:

Olivia Fan
Hi, my name is Olivia and I am a sophomore intending to double major in Computer Science and Statistics. I am interested in exploring the real-world phenomenon of machine learning algorithms and wish to pursue graduate school after graduating.

Nianli Peng
I am a junior pursuing an interdepartmental major in CS and Stats as well as a major in mathematics. I am interested in the intersection of all three subjects.

Tony Tian
My name is Tony Tian, a rising junior at Duke University. Majoring in Computer Science and Economics, I'm currently interested in machine learning and the intersection between CS and Economics. I would like to pursue graduate school after Duke. I enjoy running and like to listen to classical music during my free time.
Description: As data-driven algorithmic systems become increasingly pervasive in the real world and make decisions/optimizations that directly impact humans, one fundamental concern is that these systems be designed with fairness in mind. For example: When building a classifier to decide who should receive a loan (i.e., who is “credit worthy”) how do we ensure that different demographic groups are treated equitably, keeping in mind past bias in this and other areas of societal decision making? There is an established literature in machine learning and computational economics that has developed substantially over the last decade addressing these kinds of issues from an algorithmic perspective.
One algorithmic problem for which fairness is less well understood is reinforcement learning, where the consequences of the actions of the algorithmic decision maker may be initially unclear and may impact the future state of the world. This problem was introduced in an ICML 2017 paper by Jabbari et al, but we propose to follow-up in a very different model; rather than constraining the policy space for fairness, we will consider the problem of multi-objective reinforcement learning where the objectives represent different persons or groups of persons to whom the algorithm wishes to be fair. See recent work, for example, in ICML 2020 by Siddique et al. For example, you can imagine a reinforcement learning AI that acts as a personal assistant whose decisions impact multiple individuals, or a loan-granting algorithm that learns over time but seeks to be fair across demographic groups. Multi-objective reinforcement learning has been studied in classical and modern deep learning forms (see, e.g., JMLR 2014 by Van Moffaert and Nowe and ICML 2019 by Bellemare et al, respectively). Our goal is to synthesize research from reinforcement learning and algorithmic fairness to design an efficient and effective reinforcement learning algorithm that learns fair policies.
Goals/Deliverables:
- Extensive literature review in modern reinforcement learning and algorithmic fairness culminating in a substantial annotated bibliography.
- Model of the problem informed by the literature review along with motivating examples and appropriate definition(s) of fairness.
- Creation of one or more novel algorithms based on modifications to existing techniques.
- Implementation of algorithms in code.
- Experimentation on selected or novel constructed environments.
- Final goal is a research manuscript to be submitted for publication during AY 22-23 at an AI or algorithmic fairness conference.
Background/Prerequisites: Experience with data-driven algorithms. Mathematical maturity sufficient to read and assess mathematical models and proofs. Experience with AI/ML in Python is a plus. Students could be more interested in the theory or the experiments/application, a mix would be good.

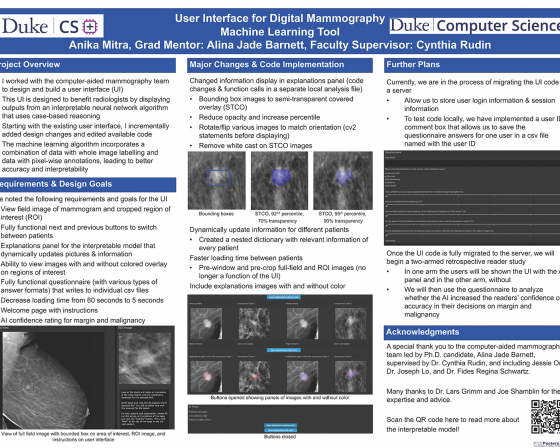
Lead: Cynthia Rudin
Participating Students:

Anika Mitra
I am a rising junior at Duke University from Bethesda, Maryland. I am currently pursuing studies in Computer Science (with a concentration in Artificial Intelligence and Machine Learning) and Mathematics. I hope to apply these skills in the intersection of AI and public policy, focusing on eliminating algorithmic bias in areas like healthcare.

Gaurav Parikh
I am a rising senior from New Delhi, India studying Data Science. I enjoy interdisciplinary research and am particularly interested in the intersections of finance and data science. I am currently involved in research on how data informs public policy-level decisions. After Duke, I hope to work for a few years in the startup space before pursuing graduate school.

Rui Xin
Hi! I'm a junior majoring in Mathematics and Computer Science. I'm interested in Machine Learning and would like to pursue graduate school after Duke.

Lead: Maciej Mazurowski
Participating Students:

Mohammed Elmzoudi
My name is Mohammed Elmzoudi, from Fuquay Varina, North Carolina. I love studying CS and machine learning, and plan to continue learning more about them at Duke and through the CS+ program.

David Han
Hello, I am a rising sophomore from Chapel Hill planning to double major in Stats and CS, with plans to pursue a PhD and / or a career in the tech sector after Duke.

Easop Lee
My name is Easop Lee, a rising senior double majoring in ECE and Physics. I am originally from Seoul, South Korea, but I went to high school in Baltimore. I intend to pursue a graduate degree in ECE after graduation. I am especially interested in deep learning and quantum computing. Outside of academics, I am a member of the varsity swim team at Duke.

Ashka Shah
Hello! My name is Ashka Shah and I from Mason, Ohio. I am currently studying Biology, Computer Science, and Global Health, and am interested in the intersection of health equity and technology. After Duke, I would like to pursue medical school or work in health technology, as I would love to work at the intersection of these three fields.
Description: In this project we ask the question: "Will a convolutional neural network trained on medical imaging data from one institution perform well on data from another institution?". This is a crucial question when it comes to practical implementation of machine learning algorithms in medicine. In this project, students will be exposed to concepts from the field of deep learning as well as become familiar with medical imaging data. You will have an opportunity to implement and test convolutional neural networks and will work as a part of a team including multiple experts in machine learning. The project will conclude in a collaborative paper.
Goals/Deliverables: We will share code and write a collaborative paper at the end of the project.
Background/Prerequisites: The students should have strong programming skills in Python and some experience in writing code involving convolutional neural networks.

Lead: Pankaj Agarwal
Participating Students:

Ashley Hong
I'm from Chapel Hill, so Duke has always been on my radar. I am double majoring in Electrical and Computer Engineering and Computer Science, and I plan on going straight into industry after college. After gaining some work experience, I would potentially go back to school to complete a graduate degree as well. Outside of school, I enjoy playing soccer and learning the guitar. I am very excited to work on the Multi-Robot Motion Planning project this year and be a part of the CS+ community!

Ellie Kim
I am currently a third-year undergrad student at Duke University studying Computer Science. I was born in Chicago but I grew up in Chapel Hill, North Carolina. After Duke, I am interested in possibly attending graduate school for computer science. In my free time, I enjoy dancing hip-hop and open style as well as writing poetry.
Description: Multi robot systems are widely deployed in logistics, a variety of civil engineering and nature preserving tasks, and in agriculture, to name a few areas. With the broad progress in robotics, the task of planning the motion of multi robot systems with performance guarantees is of increasing importance. One aspect of the autonomy of a multi-robot system is its collision-free motion capability, namely the ability of its constituent robots to navigate in their workspace without colliding with obstacles nor with other robots. The basic motion-planning problem for a team of robots is to plan such collision-free paths for the robots between given free start and final positions. Specifically, we are given a family of robots, each modeled as a simple shape (e.g. disc), moving in a planar environment. Given a set of initial and final placements for each robot, the goal is to find a good quality motion plan for all the robots. The quality of a motion plan is measured by the sum of lengths of the paths or the maximum taken by a robot to reach its destination. The overall goal is to design scalable algorithms for finding high-quality motions.
Goals/Deliverables: Adapt existing algorithms, implement them, and test their efficacy and efficiency.
Background/Prerequisites: Basic knowledge of algorithms and data structures and strong coding skills.

Lead: Fred Dietrich, Associate Professor, Molecular Genetics and Microbiology
Participating Students:

Molly Borowiak
I'm a rising senior from Apex, NC. I'm studying computer science, with additional minors in economics and computational biology. After Duke, I aspire to join a graduate program, preferably in genomics or another field in comp bio. In my freetime, I enjoy listening to and writing fiction podcasts.

Sophia Leeman
I am a Biomedical Engineering and Computer Science major from Charlotte, NC who is passionate about creating computer science innovations that impact human health. As part of project protein fold, I will contribute to these innovations by developing a pipeline to predict protein misfolding from genetic mutation data and compare these structures to give insight into human genetic disease. My interest in protein misfolding is sparked by my research experience in the Musah Lab at Duke, where I am employing CRISPR-Cas9 Technology and Stem Cell Technology to study the impact of genetic mutations on the development of kidney disease. Outside of research, I am involved in a variety of organizations at duke, including the Engineering Student Government, Duke eNable, and Classical Voice groups.

Benjamin Peng
My name's Ben and I'm a rising sophomore. I was born in San Diego and lived there for 18 years. I'm currently pursuing a dual major in Computer Science and Classical Languages, potentially with a minor in Computational Biology and Bioinformatics. After Duke, I would be interested in a career in computational biology or machine learning, although I'm not entirely sure yet.

Teodora Petkova
I am Teodora and I come from Bulgaria. I am a rising senior at Duke Kunshan University, and I am majoring in data science. I love math and coding, and I am super excited about my CS+ project on comparing protein structures. Whenever I am not working on my computer, you can find me playing table tennis or reading a good book.

Jake Spruance
I'm Jake, and I'm from Kennett Square, PA. To me, computational biology is a super cool field because there's a lot of potential for impact. There's still so much we don't know about disease and our own biology, and I think leveraging bioinformatics and new computational tools is a great way to learn more. I hope to pursue a graduate degree in a related field.
Description: In recent years experimental methods to determine three-dimensional protein structures have improved significantly, and in July 2021 the source code for Alphafold from Deepmind has been released. Alphafold is considered by many to be a significant improvement in the ability to predict protein structures. These developments open up new areas to explore in biological and biomedical research. In the past the fields of genetics and protein structure determination have barely overlapped. This may well change over the next few years. For “Project Protein Fold” we intend to ask students to explore the following big question: Can protein structure, either experimentally determined or predicted, inform us on the nature of polymorphism found in human disease?
Goals/Deliverables: Develop a pipeline that can extract polymorphism data for specific human genes, generate predicted protein structures for each gene for each allele, and determine the spectrum of structural changes resulting from common, rare, disease causing, non- disease causing, and potential but not observed alleles. This information is publicly available from several sources. The primary challenges here are selecting an appropriate algorithm to compare structures. A secondary challenge is deciding which portion of the protein sequence is necessary to use in this analysis. These are both non-trivial problems. A final issue is how to put the results together in a generally comprehensible form, comprehensible to those working in the area of human genetics.
Background/Prerequisites: Programming skills, especially in Python, comfortable working with data, some experience in algorithms and/or machine learning helpful, experience in computational biology is a plus.

Lead: Rong Ge
Participating Students:

Angikar Ghosal
I am Angikar Ghosal, a sophomore from Kolkata, India who is majoring in Computer Science and Mathematics and wants to be a professor eventually!

Tina Hu
I'm a rising junior from Shanghai, China. I'm majoring in computer science and statistics and minoring in mathematics. I'm interested in computer science research, and plan to pursue a graduate degree after Duke.

Jupiter Zhu
I am Xingyu Zhu from Beijing, China. As a senior majoring in Math and CS, I will be graduating next semester. I am interested in theoretical machine learning and would like to pursue a doctoral degree in that field after I graduate. In my free time, I like to do competitive cycling and play the electric guitar.
Description: Recent work [LCDR18] has shown (remarkably) that it is possible to do machine translation in an entirely unsupervised way through alignment of text embedding spaces across languages. This line of work has sparked significant interest in understanding how text embedding spaces compare to another, and several works [AMJ18, SRV18, VRS20] have considered measures for comparing embedding spaces across languages. However, seemingly little work has been done on understanding how embedding spaces differ across a single language when trained with different methods or using different random initializations. The recent results of [AZL21] have shown that different model initializations can lead to learning different features of the input data, and the goal of this project is to understand whether this is also the case in the context of learning text embeddings. Namely, we hope to first apply some of the existing metrics in the aforementioned works to understanding how much randomness affects learned text embedding spaces, and then we also hope that these initial experiments will potentially lead to new insights for either (a) comparing embeddings, (b) training better text embedding models, or (c) both.
References:
- [AMJ18] David Alvarez-Melis and Tommi Jaakkola. Gromov-Wasserstein alignment of word embedding spaces. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1881–1890, Brussels, Belgium, October-November 2018. Association for Computational Linguistics.
- [AZL21] Zeyuan Allen-Zhu and Yuanzhi Li. Towards understanding ensemble, knowledge distillation and self-distillation in deep learning, 2021.
- [LCDR18] Guillaume Lample, Alexis Conneau, Ludovic Denoyer, and Marc’Aurelio Ranzato. Unsupervised machine translation using monolingual corpora only, 2018.
- [SRV18] Anders Søgaard, Sebastian Ruder, and Ivan Vuli ́c. On the limitations of unsupervised bilingual dictionary induction, 2018.
- [VRS20] Ivan Vuli ́c, Sebastian Ruder, and Anders Søgaard. Are all good word vector spaces isomorphic?, 2020
Goals/Deliverables: A report (potentially turned into a research paper).
Background/Prerequisites: Familiarity with linear algebra, machine learning, willing to learn some deep learning framework (most likely pytorch).

Lead: Xiaowei Yang
Participating Students:

Carl Dong
I'm a rising sophomore from Suzhou, China, and I plan to major in ECE and CS. I'm excited about this research opportunity. After graduating from Duke, I look forward to pursuing tech-related entrepreneurship.

Jaewon Jung
I am from Raleigh, North Carolina, studying computer science and economics at Duke. I 'm super excited to join a team of students exploring the field of computer science!
Description: Web cache is an essential service on the Internet to speed up page loading. Current websites usually employ Content Distribution Networks (CDNs) as a third-party cache service. Such a practice requires that a website developer correctly configures web contents as cacheable and non-cacheable. A mistake made in configuration may cause a user's private data to leak to other users. We plan to conduct a measurement study of web cache misconfigurations that may lead to private data leakage. The misconfigurations include HTTP header misconfigurations or CDN misconfigurations. The challenge of this project is to develop a methodology to detect private data on a website. We have a preliminary method that differentiates private and public requests by inspecting the responses of authenticated and unauthenticated accounts. However, such a method may lead to a high false-positive rate because of the prevalent dynamic requests present in the web ecosystem. We expect to improve such a method in this project.
Goals/Deliverables: The ideal deliverables will be a project write-up that can be published at systems or networking conferences such as USENIX NSDI, ACM SIGCOMM, and ACM IMC.
Background/Prerequisites: Students who are interested in this project should be familiar with one programming language and web development. Students will learn and practice the knowledge of network protocols and network security in this project.